All papers that have not been peer-reviewed will not appear here, including preprints. You can access my all of papers at 🔗Google Scholar.
2026

JanusQuant:Accurate and Efficient 2-bit KV Cache Quantization for Long-context Inference
Chengyu Sun, Yaqi Xia, Hulin Wang, Donglin Yang, Xiaobo Zhou, Dazhao Cheng
ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming (PPoPP) 2026 ConferenceCCF-A
We present JanusQuant, a 2-bit KV cache quantization system that achieves both high accuracy and end-to-end efficiency through algorithm–system co-design for long-context generation tasks.
2025
MXBLAS:Accelerating 8-bit Deep Learning with a Unified Micro-Scaled GEMM Library.
Weihu Wang†, Yaqi Xia†, Donglin Yang, Xiaobo Zhou, Dazhao Cheng(† equal contribution)
2025 International Conference for High Performance Computing, Networking, Storage, and Analysis (SC) 2025 ConferenceCCF-A
We present MXBLAS, a high-performance MX-GEMM library that unifies support across the full spectrum of MX-format variations.
Voltrix:Sparse Matrix-Matrix Multiplication on Tensor Cores with Asynchronous and Balanced Kernel Optimization
Yaqi Xia†, Weihu Wang†, Donglin Yang, Xiaobo Zhou, Dazhao Cheng(† equal contribution)
2025 USENIX Annual Technical Conference (ATC) 2025 ConferenceCCF-A
We introduce Voltrix-SpMM, a revolutionary GPU kernel design for sparse matrix-matrix multiplication.
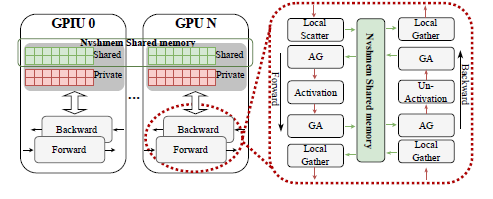
Harnessing Inter-GPU Shared Memory for Seamless MoE Communication-Computation Fusion
Hulin Wang, Yaqi Xia, Donglin Yang, Xiaobo Zhou, Dazhao Cheng
ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming (PPoPP) 2025 ConferenceCCF-A
We introduce CCFuser, a novel framework designed for efficient training of MoE models.
2024
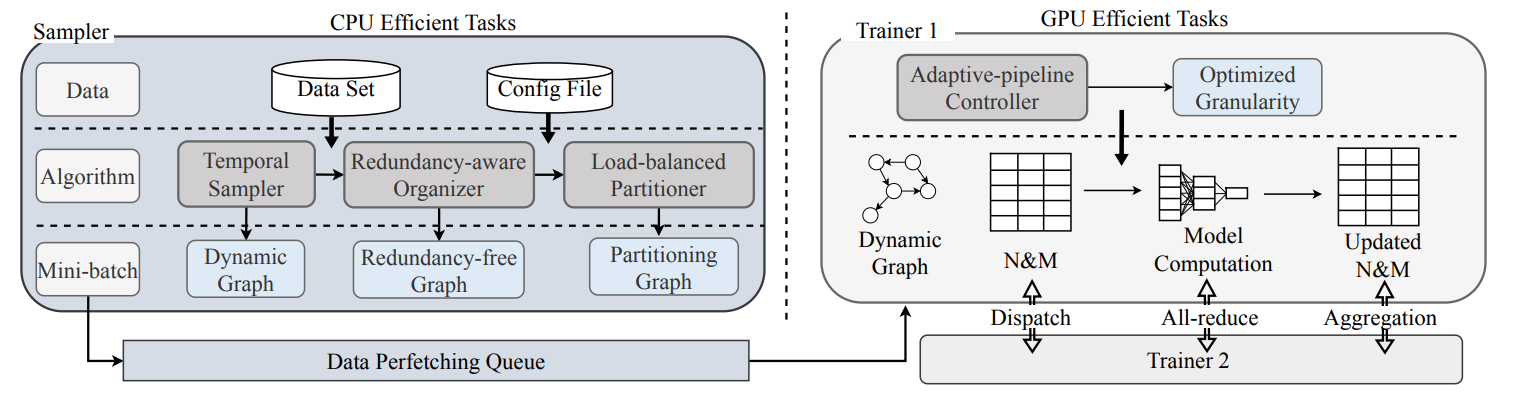
Redundancy-free and load-balanced TGNN training with hierarchical pipeline parallelism
Yaqi Xia, Zheng Zhang, Donglin Yang, Chuang Hu, Xiaobo Zhou, Hongyang Chen, Qianlong Sang, Dazhao Cheng
IEEE Transactions on Parallel and Distributed (TPDS) 2024 JournalCCF-A
This work introduces Sven, a co-designed algorithm-system library aimed at accelerating TGNN training on a multi-GPU platform.
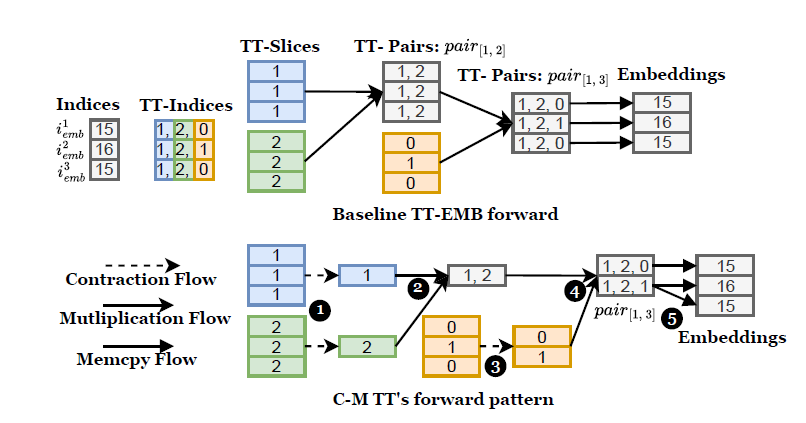
Accelerating Distributed DLRM Training with Optimized TT Decomposition and Micro-Batching
Weihu Wang, Yaqi Xia, Donglin Yang, Xiaobo Zhou, Dazhao Cheng
The International Conference for High Performance Computing, Networking, Storage, and Analysis (SC) 2024 ConferenceCCF-A
We introduce EcoRec, an advanced library that boosts DLRM training by integrating TT decomposition with distributed training.
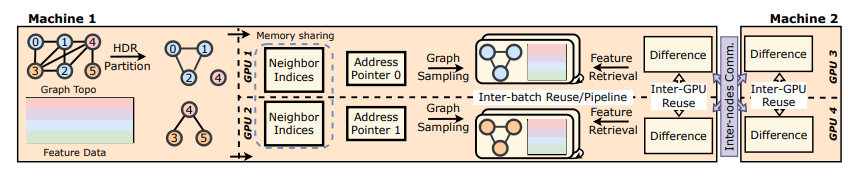
Scaling New Heights :Transformative Cross-GPU Sampling for Training Billion-Edge Graphs
Yaqi Xia, Donglin Yang, Xiaobo Zhou, Dazhao Cheng
The International Conference for High Performance Computing, Networking, Storage, and Analysis (SC) 2024 ConferenceCCF-A
In this paper, we introduced HyDRA, a pioneering framework for sampling-based GNN training on large-scale graphs.
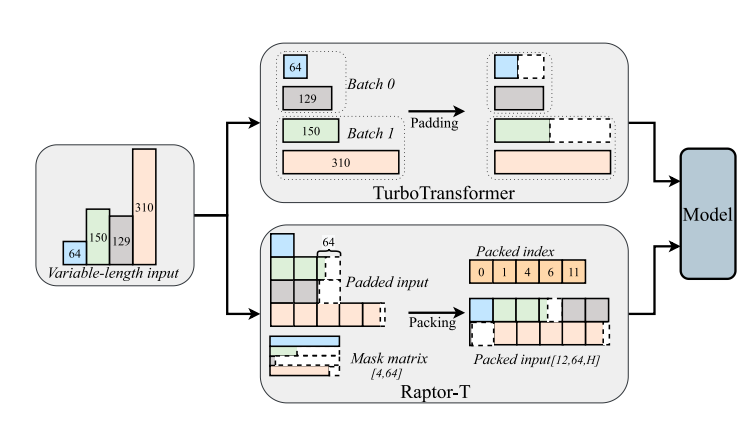
Raptor-T :A Fused and Memory-Efficient Sparse Transformer for Long and Variable-Length Sequences
Hulin Wang, Donglin Yang, Yaqi Xia, Zheng Zhang, Qigang Wang, Jianping Fan, Xiaobo Zhou, Dazhao Cheng
IEEE Transactions on Computers (TC) 2024 JournalCCF-A
We present Raptor-T, a cutting-edge transformer framework designed for handling long and variable-length sequences. Raptor-T harnesses the power of the sparse transformer to reduce resource requirements for processing long sequences while also implementing system-level optimizations to accelerate inference performance.
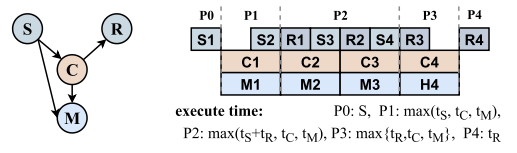
MPMoE :Memory Efficient MoE for Pre-Trained Models With Adaptive Pipeline Parallelism
Zheng Zhang, Yaqi Xia, Hulin Wang, Donglin Yang, Chuang Hu, Xiaobo Zhou, Dazhao Cheng
IEEE Transactions on Parallel and Distributed (TPDS) 2024 JournalCCF-ABest Paper Runner-up
In this paper, we present the design and implementation of MPMoE, a high-performance library that accelerates MoE training with adaptive and memory-efficient pipeline parallelism.
2023
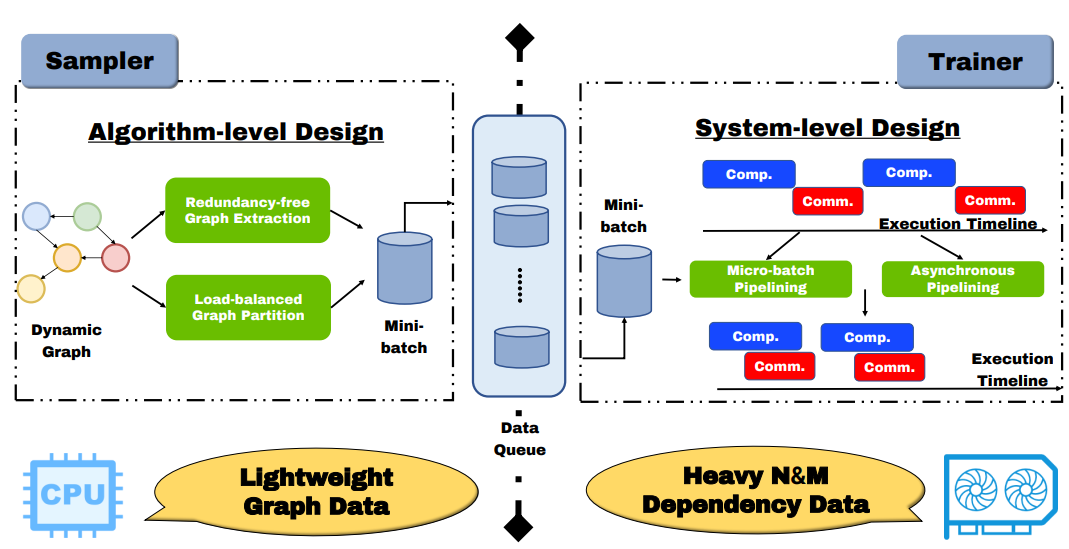
Redundancy-Free High-Performance Dynamic GNN Training with Hierarchical Pipeline Parallelism
Yaqi Xia, Zheng Zhang, Hulin Wang, Donglin Yang, Xiaobo Zhou, Dazhao Cheng
The 32nd International Symposium on High-Performance Parallel and Distributed Computing (ACM HPDC) 2023 ConferenceCCF-ABest Paper Nomination
This paper presents Sven, an algorithm and system co-designed TGNN training library for the end-to-end performance optimization on multi-node multi-GPU systems.

MPipeMoE :Memory Efficient MoE for Pre-trained Models with Adaptive Pipeline Parallelism
Zheng Zhang, Donglin Yang, Yaqi Xia, Liang Ding, Dacheng Tao, Xiaobo Zhou, Dazhao Cheng
IEEE International Parallel and Distributed Processing Symposium (IPDPS) 2023 ConferenceCCF-B
In this paper, we present the design and implementation of MPipeMoE, a high-performance library that accelerates MoE training with adaptive and memory-efficient pipeline parallelism.
2021
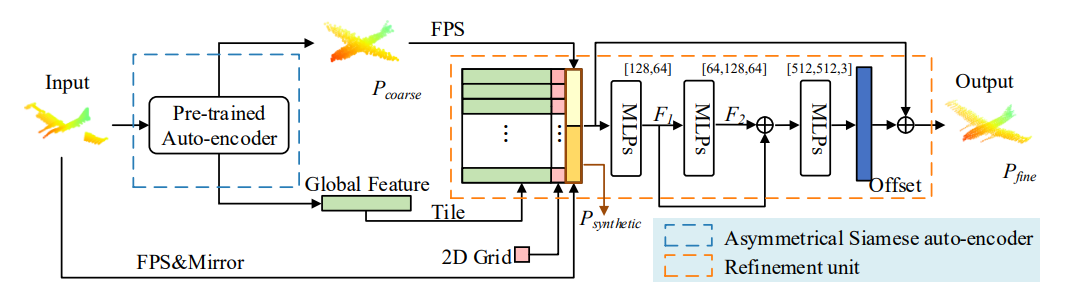
ASFM-Net :Asymmetrical Siamese Feature Matching Network for Point Completion
Yaqi Xia†, Yan Xia†, Wei Li, Rui Song, Kailang Cao, Uwe Stilla(† equal contribution)
Proceedings of the 29th ACM international conference on multimedia (ACM MM) 2021 ConferenceCCF-A
We tackle the problem of object completion from point clouds and propose a novel point cloud completion network employing an Asymmetrical Siamese Feature Matching strategy, termed as ASFM-Net.